¿Es posible la Web semántica?
No quisiera detenerme demasiado en la definición de Web semántica, o web inteligente, esa que transforma la Web de servidora de archivos a bases de datos, en la que la inteligencia está en las conexiones y las máquinas "se entienden", es decir, pueden conectarse, como señala Nova Spivack en esta presentación. Pero algunas pistas pueden iluminarnos sobre el tema aquí, o aquí. También podemos revisar algunas de las aplicaciones que se están desarrollando y casos de uso por parte de diferentes instituciones.
Quisiera enfocarme en tres preguntas, las planteadas por mi tutora Dolors Reig como guía para realizar esta actividad en el marco de la materia "La educación en la tercera década de la web" que estoy cursando actualmente. Parece que un impacto inesperado de esta maestría consistirá en revitalizar este blog. ¡Enhorabuena por ello!
¿Qué dificultades existen para la implantación de la web semántica?
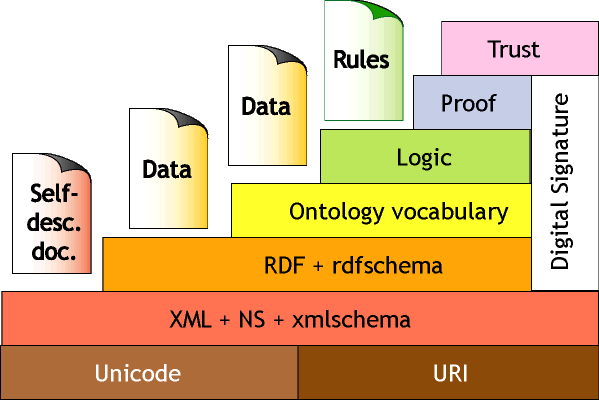
Las dificultades para su implantación radican esencialmente en los diferentes formatos que coexisten en la web, que desde su origen constituye un escenario heterogéneo y muy diferente al que usaban las disciplinas clásicas vinculadas con la documentación. En este sentido, las ontologías constituyen herramientas propuestas para facilitar el reconocimiento, comparación y combinación de recursos web con diferente estructura (Pedraza-Jiménez et al 2007). De esta manera se pretende facilitar el proceso de recuperación de la información y alcanzar así el séptimo nivel o capa de la web semántica: el de la confianza (Codina y Rovira 2006).
La imagen muestra la arquitectura de la web semántica y sus siete niveles, según Tim Berners-Lee.
¿Qué grandes compañías apuestan por ella?
Como parte de su competencia por captar usuarios, la siempre vigente tensión entre las conocidas Microsoft y Google se manifiesta particulamente en estos terrenos. En 2008 Microsoft adquirió Powerset e incorporó la búsqueda semántica a sus posibilidades, generando el buscador Bing, con gran éxito. En 2010, Google hizo lo propio con Metaweb, líderes en web semántica. Son apenas dos ejemplos de una "carrera armamentista", en la que participan muchos, hasta los menos conocidos (al menos para mí), como el buscador Swoogle, desarrollado como proyecto de la UMBC ya en 2004, o la austríaca SWC, quien cuenta entre sus clientes prestigiosos bancos y empresas en tres continentes. Existen además muchas otras compañías dedicadas al "negocio" de significar los contenidos.¿Por qué adoptan esa estrategia?
Las grandes compañías se benefician del mayor consumo de los usuarios. En este sentido, si la información que buscamos puede recuperarse en resultados de mayor calidad, la publicidad semántica puede beneficiarse de generar ofertas que resulten de interés para los usuarios; parafraseando a Dave Viner: “La publicidad, cuando está perfectamente adaptada a nuestros intereses, es contenido".
Para seguir pensando
De manera análoga a este ejemplo, una escena de la película Yo, Robot (2004) ambientada en el no tan lejano 2035 y basada tangencialmente en el libro homónimo de Isaac Asimov, señala a mi entender, algunos de nuestros "temores" sobre la posibilidad de las "máquinas inteligentes" y sus capacidades/posibilidades de aprendizaje, poniendo también en el tapete nuestros miedos frente a la tecnología.
"Eres solo una máquina. Una imitación de la vida. ¿Puede un robot escribir una sinfonía?"
El tema da para profundizar mucho más debido a su complejidad y múltiples formas de abordaje (incluyendo otras posibilidades ya reales de robots, ¡gracias Elisa!) . Quizá en la medida en que podamos superar esos pequeños escollos, al menos como punto de partida, podremos avanzar para lograr (y seguir) construyendo una web inteligente. La revolución de la web está ocurriendo, como señalaba Ryan King, co-fundador de microformats.org ya en 2005. Y aunque no quede totalmente clara mi opinión a partir de todo lo expuesto anteriormente, sí creo que esta web es posible. Nosotros somos la web.
Otras fuentes consultadas:
La cita de Viner fue tomada de Reig, D. (sin año). "Educación en la tercera década de la web. Unidad I. Maestría en Entornos Virtuales de Aprendizaje, que también sirvió para ordenar ideas y como base para buscar referencias.
buenazo... lo que más reflexión me produce el concepto de la web semántica tiene que ver con quién controla/accede a la información integrada cuando es de tipo personal.
ResponderEliminarpodemos construir redes ideológicas? qué puede hacer un gobierno autoritario con eso? qué puede hacer un grupo extremista?
creo que la clave en esas cosas es que justamente sean las máquinas las que resuelven esas cosas y no las personas (con sus claro-oscuros, sus dudas, sus temores, sus creencias)... la maquina tiene la excelente capacidad de no juzgar en términos humanos.
me explico?
que al abrir un correo, gmail ponga a un costado publicidad en base a los contenidos de mis charlas profesionales o con amigos, no me preocupa, pues lo hace una maquina que no me juzga, me propone más contenidos a partir de mis contenidos.... me preocuparía si hay un toque "humano" que dice si mis correos están bien o mal.
volviendo a tu texto y a tu blog... me encanta pues dispara más cosas, no solo desde los hipervínculos sino desde la reflexión y la invitación a la re-invención.
El gran tema es lo primero que planteás, porque ahí está el meollo del asunto. La información es poder... y eso puede ser un problema según quién y cómo la gestione.
ResponderEliminarTotalmente de acuerdo con lo otro, las máquinas pueden tener esa "objetividad", pero no debemos olvidar de todas maneras que somos nosotros los que le enseñamos a la máquina.
Sobre lo último, gracias de nuevo, sabés que fuiste de los primeros que celebró que me pusiera a escribir (como lo dice una de las primeras entradas).
Habrá que hacerse tiempo, parece que la maestría va a propiciar estos espacios :-)